- 这是CVPR2020的一篇论文
- 当前的目标检测根据于GTbox的IOU把anchor标注为背景或前景类别的分类标签,使得一些不完善的label给训练带来了噪音,提高了训练难度。本文提供了一个 cleanliness score 作为一个soft label,并作为某些trick的权重,提高了目标检测的精度,在retinanet上涨点了2%的map
- 分类的难度有一点原因是以下现象导致的:由于anchor的label是根据与GT的IOU大小确定的,所以当某个anchor与GT的IOU大于0.5时,也就是说只要目标的一部分进入anchor,就要求分类器把这个anchor分类为某个前景类别,而对于分类器来说可能只看到了这个目标的一部分而已,这就导致了训练的难度;
- 这种anchor标注的方式可以说是不合理的,因为一个anchor包含部分是否是一个目标没有明显的界限,这和图像分类不同,一个目标是否出现是很明确的,而这里依靠出现的部分的大小比例,根据人设置的阈值,来粗暴地分割为是和否,是不合理的
- 如图也可以明显感受到,根据IOU大小来确定一个anchor应该被分类为什么有时候是极其noisy和不合理的:

- 并且这种噪声给采样方法和Focal Loss带来更大的影响,因为他们导致很大的loss
- 因此对于每个anchor,我们需要的不是一个label,而是一个score,能够衡量一个anchor被回归到正确位置和分类为正确标签的可能性,并且最好是网络自己产生的,连续的score而不希望是人为定义的。本文根据分类的score和localization的精确度来确定这个值。并且这个score将用来确定某个anchor在loss中的权重,从而降低noisy anchor的影响
- 这个值的定义如下:
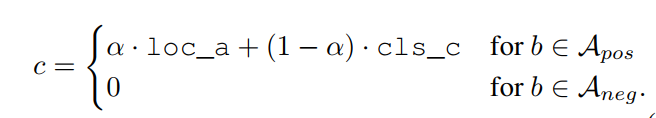
- 可见,score只对按原有方法归类为positive的anchor进行。这里的loc_a表示经过回归支路进行调整后的bbox与GTbox的IOU,cls_c表示分类输出(猜测是经过softmax或者sigmoid后的概率值,原文没有给代码无法判断)
- 举个例子,原来的二分类损失如下:
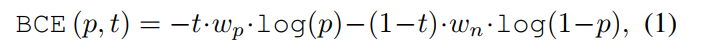
其中t为1或0,但现在可以是0-1之间的一个离散值。 - 同时,这个c可以用来当作focal loss的权重:

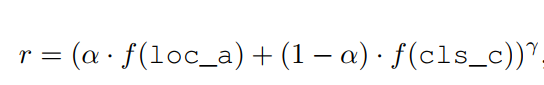
其中,f为:
f
(
x
)
=
1
1
−
x
f(x)=\frac{1}{1-x}
f(x)=1−x1
完整算法如下: